🌐 Local · macOS Apple Silicon · Free iOS Companion · GDPR
⚡ New in v1.6.3 — much faster
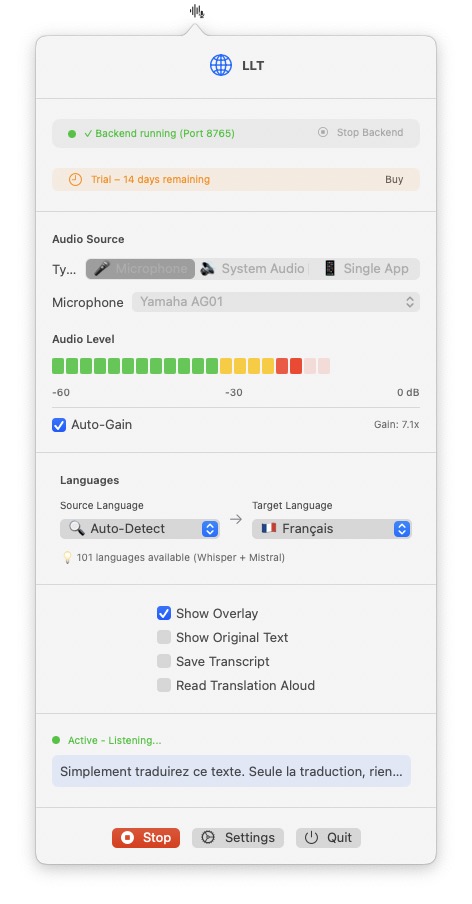
Translate, transcribe, dictate — output almost anywhere.
Most tools do one thing well. LLT does the whole pipeline — translate, transcribe and dictate, 100% local on Apple Silicon (Whisper · Parakeet · Mistral), with optional on-device LLM sentence-polishing. Then send it live to OBS, VRChat or vMix, in your own design. The free iOS companion turns your iPhone into a wireless mic — and can even start LLT on your Mac across the network; in the field without Wi-Fi, switch to direct cloud engines (Pro). GDPR-compliant, no extra costs, all in one system.
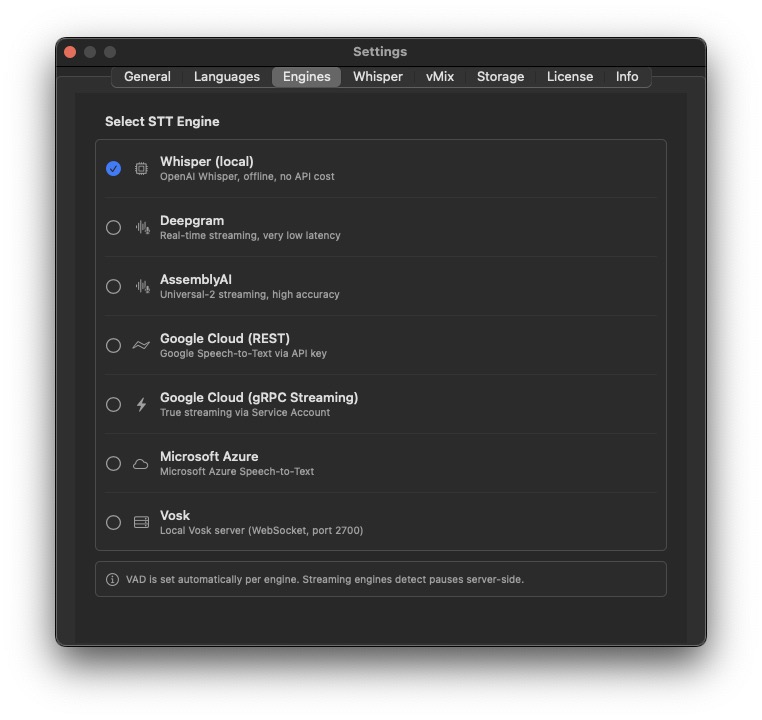
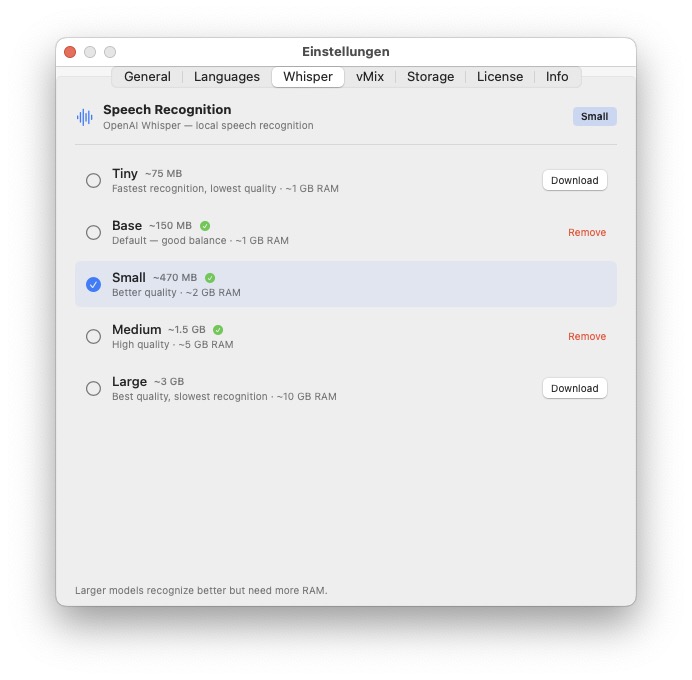
Whisper
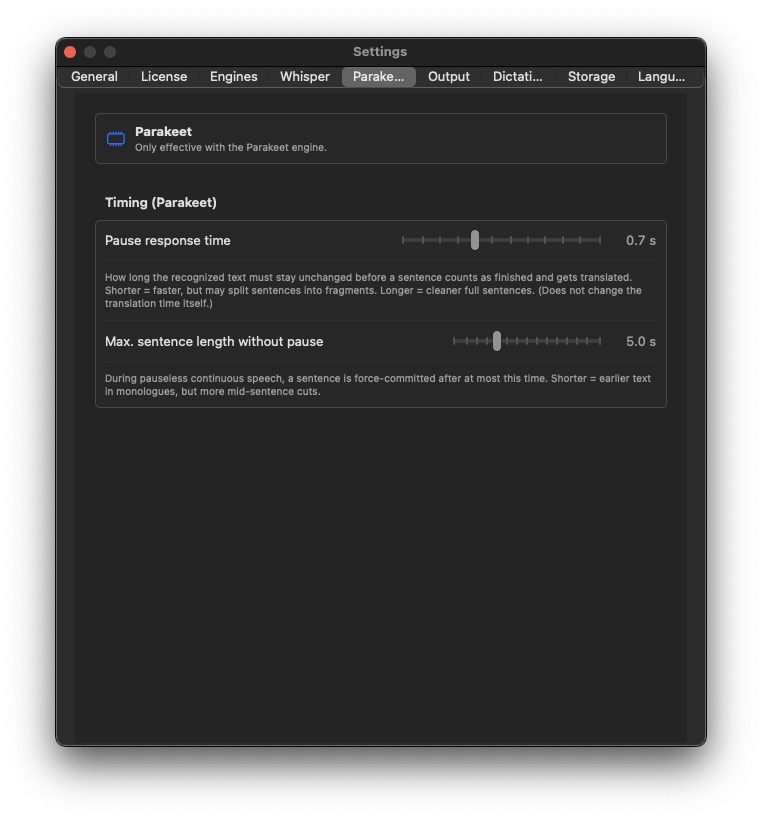
Parakeet
Mistral (local LLM)
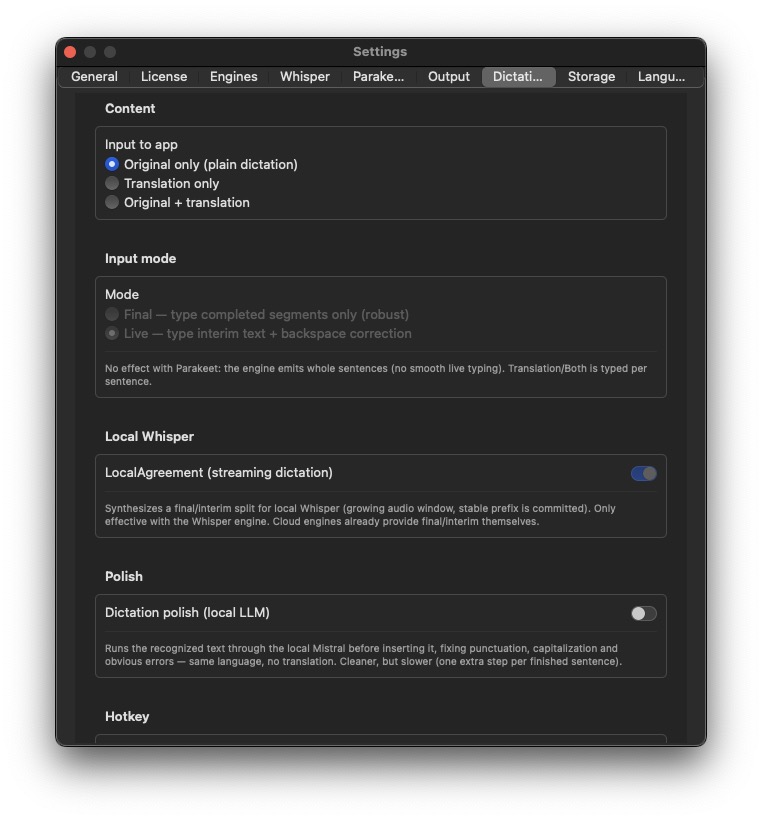
LLM Sentence-Polishing
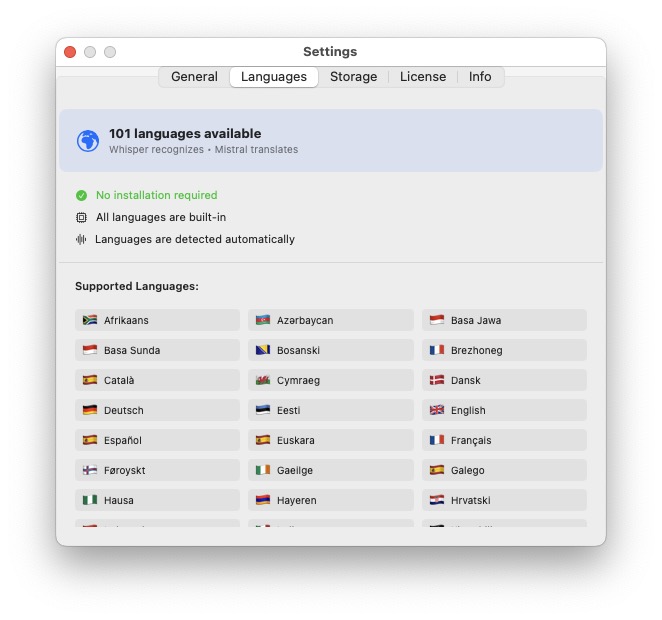
101 Languages
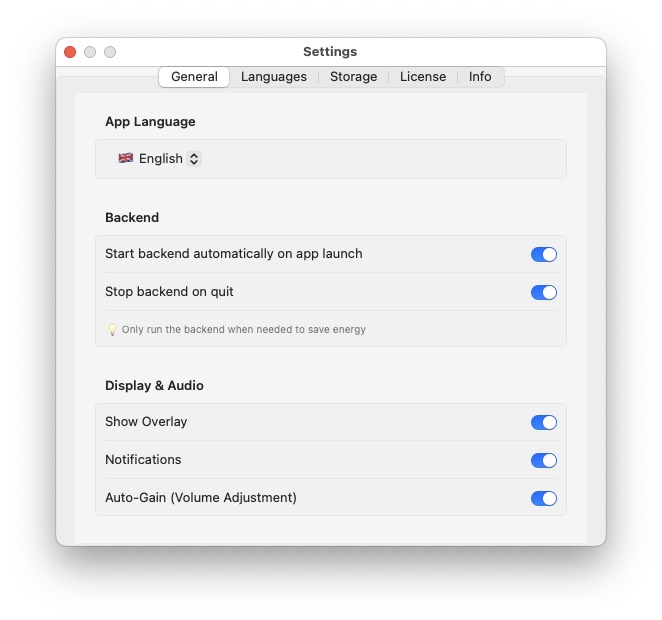
100% Local · GDPR
Dictation (⌘⌥D)
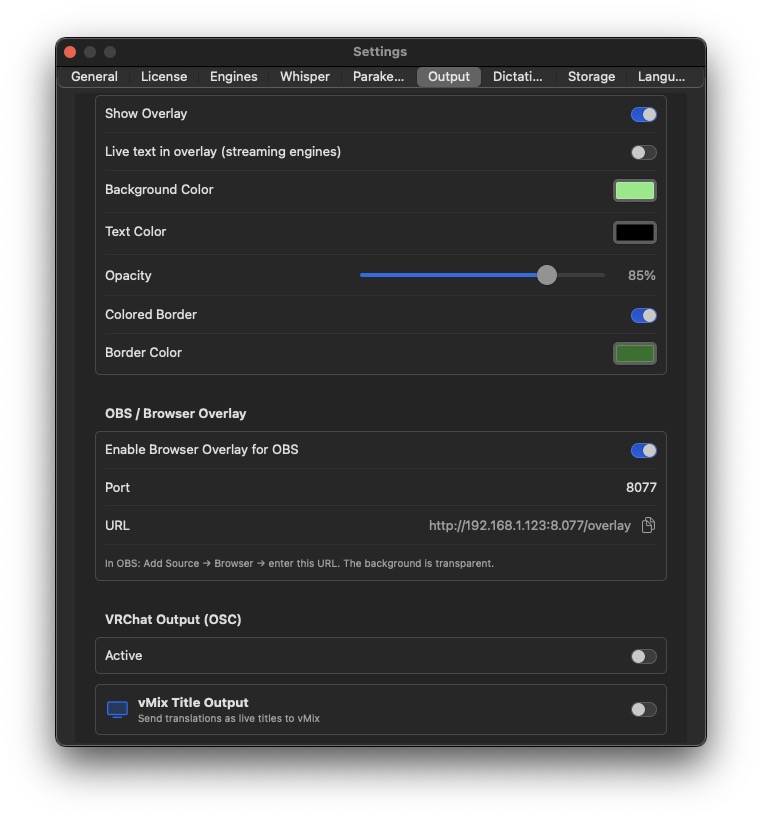
OBS Browser Source
VRChat (OSC)
vMix Title
Free iOS Companion
Cloud Engines (Pro)